An open-source framework that provides
realtime infrastructure and in-transit message processing
for web applications.
Easy to Manage & Deploy
Easy to Manage & Deploy
Ekko abstracts away the complexity of working with cloud
infrastructure by automating the deployment process.
Modular and Flexible
Modular and Flexible
Ekko Functions are serverless functions that can be customized for
your realtime needs and reused across applications.
Case Study
1. Ekko 101
Ekko is an open-source framework that allows developers to easily
deploy realtime infrastructure for their applications. Custom
serverless functions provide a flexible, modular way to process
messages as they pass through the realtime system. It is easy to use
our command-line tool to spin up Ekko’s infrastructure, as is
deploying serverless functions to process any messages that pass
through the realtime system.
In this case study, we describe the engineering problem that Ekko
solves, that of realtime in-transit message processing. We
demonstrate how Ekko works and explain some of the key technical
challenges we encountered. Before we get into those details, we want
to explain the problem that we sought to address.
2. Realtime Web Applications
2.1 Realtime Applications are Everywhere
Realtime web applications, or realtime components within bigger
monolithic applications, are everywhere.
Any live data dashboards, such as stock prices ticking up and down
on a website, are examples of realtime web applications. The same
applies if you open the Uber app and you see your driver’s car
location moving around on the screen, or to simple chat applications
where you’re talking back and forth and you see messages as soon as
they’re sent to you.
These are all very common examples of realtime applications that we
see and use every day. In short, users want to automatically get
information updates (like messages or geo-locations) without
requesting those updates. We see more dynamic and responsive
applications being created with the use of these realtime
technologies, and alongside that we see application users
increasingly expecting realtime data.
2.2 Perceived as Instantaneous
In the context of web applications, realtime relates to what the
user perceives as happening ‘in real time’.
How fast do interactions need to be in order to be perceived as
realtime? "Anything under 100 milliseconds," and "anything within a
few hundred milliseconds," are the most common statements you'll
find when looking into realtime within the context of web
applications. (Both of these statements stem from
Robert Miller’s 1968 paper, "Response time in man-computer conversational transactions”.)
As one of the leading service providers in the realtime space,
PubNub,
has stated:
“In almost all cases, a realtime interaction has a human angle,
because one of the collaborators in any realtime data exchange is
always a human. Even in a machine to machine interaction, there is a
human sitting at the back, receiving feedback. Hence the human
perception of a realtime event is very important.”
The meaning of realtime is different in industries such as
healthcare and aerospace -- so-called ‘hard’ realtime -- where it is
specifically used to refer to systems that human lives can depend
on. This is not the type of realtime that we are addressing.
Instead, we are focusing on realtime web applications which are
specifically concerned with the user’s perception of
“instantaneous.”
Next, let's consider some of the most common communication patterns
for realtime web applications.
3. How is Realtime Implemented
There are many ways to implement realtime in an application. In this
section, we will explore a common way to achieve realtime
functionality for an app with many publishers and many subscribers.
3.1 Data Transfer Patterns: Pulling Data
At the bedrock of web communication we have traditional HTTP request
response cycles, and along with it the idea of pulling data.
When you pull data, you have data that lives in a database
somewhere. This data isn’t retrieved until a client explicitly makes
a request for the data, at which point the server responds.
As we mentioned before, realtime applications automatically update
users, without the user requesting the update. So, realtime apps
tend not to use a data pull pattern.
3.2 Data Transfer Patterns: Pushing Data
The pull pattern is distinct from the push pattern.
In the data push pattern, the client often starts with an initial
request but it keeps that connection open. Now whenever new data is
generated, it is immediately sent, or “pushed”, to the client over
the open connection.
This is the data transfer pattern that realtime applications use:
users receive updates automatically, without requesting them.
The Pub/Sub model is commonly used to describe the broad set of
behaviors associated with this data push pattern.
3.3 Messaging Pattern: 1:1 Pub/Sub
Within the Pub/Sub pattern, you will see that we no longer model
things in terms of servers and clients. We now have ‘publishers’ and
‘subscribers’, and the pattern is focused specifically on their
actual roles in the interaction.
We represent them both as browsers on iPads, but the actual hardware
doesn’t really matter. Anything that was traditionally a server or a
client can act as a publisher or a subscriber.
Within the Pub/Sub model we no longer talk about data being stored
or data being sent. Instead we think about data in terms of messages
being sent from publishers to subscribers. Those messages, in turn,
are sent or published to ‘channels’; in some contexts these are
referred to as ‘topics’, ‘queues’, or ‘rooms’.
Above is an example of a one-to-one Pub/Sub pattern. We have a
single publisher generating messages and sending them to a single
subscriber. If we take this example one step further, we can see
that the Pub/Sub model can also be used for one to many messaging.
3.4 Messaging Pattern: 1:M Pub/Sub
With this new pattern, we still have a single publisher on the left,
but now we have three subscribers on the right. Whenever the
publisher generates new messages, it sends them over to the
subscribers.
We can take this pattern even further, with a many-to-many Pub/Sub
messaging pattern.
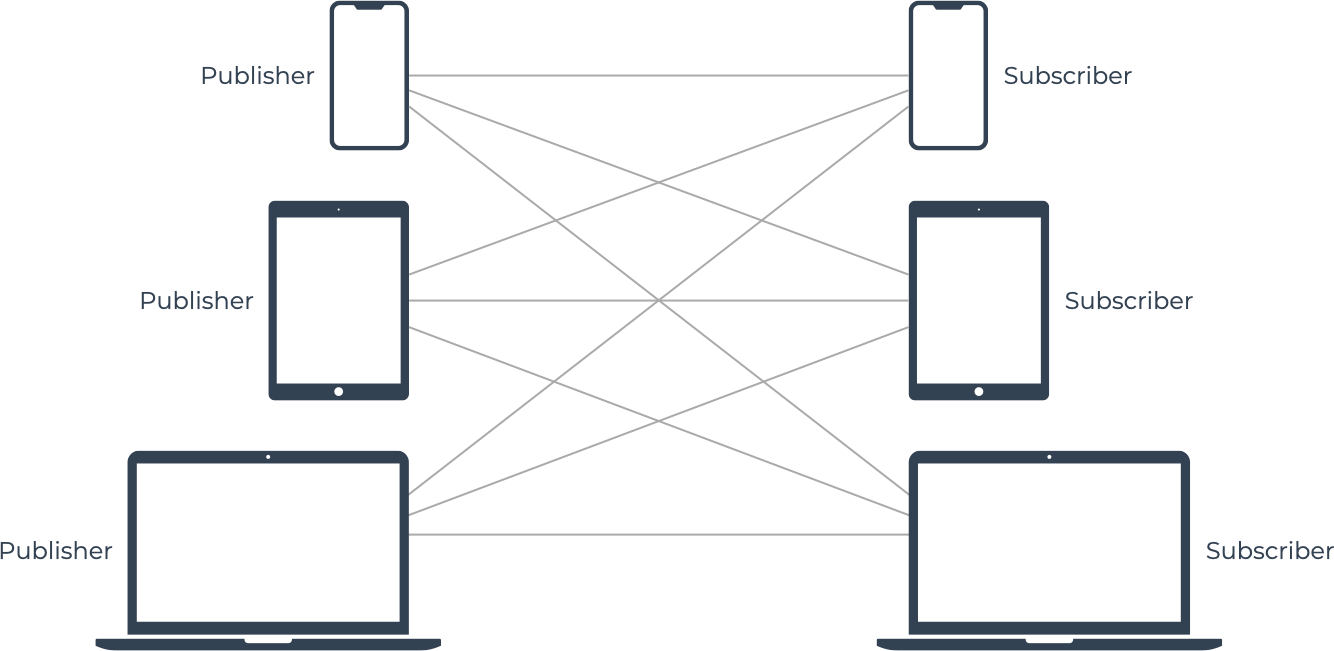
3.5 Messaging Pattern: M:M Pub/Sub
Looking at this diagram, it is easy to see how things can get
complicated very quickly. There are peer-to-peer protocols that are
specifically designed to support this many-to-many Pub/Sub pattern.
However, a centralized hub is the most common way to manage
connections for realtime applications with many publishers and
subscribers.
3.6 Messaging Pattern: Pub/Sub Hub
With this pattern, each of the publishers and subscribers have a
single realtime connection to the central hub.
When a publisher sends a message it goes to the hub and then it is
emitted to all relevant subscribers.
There is one final pattern that we commonly find in the world of
Pub/Sub: bi-directional communication.
3.7 Messaging Pattern: Bi-directional Pub/Sub
So far we have only seen examples of clients being a publisher
or a subscriber, but within realtime web applications it is
very common for devices to be both publishers and
subscribers.
If we take the common use case of a chat application, a user is a
publisher whenever they send messages, and a subscriber when they
receive them. In the above example we show various devices
publishing messages. These messages go to the central hub and are
then emitted to all relevant subscribers.
Now, we’ll look at why Websockets is the protocol of choice for a
realtime applications that use a Pub/Sub hub.
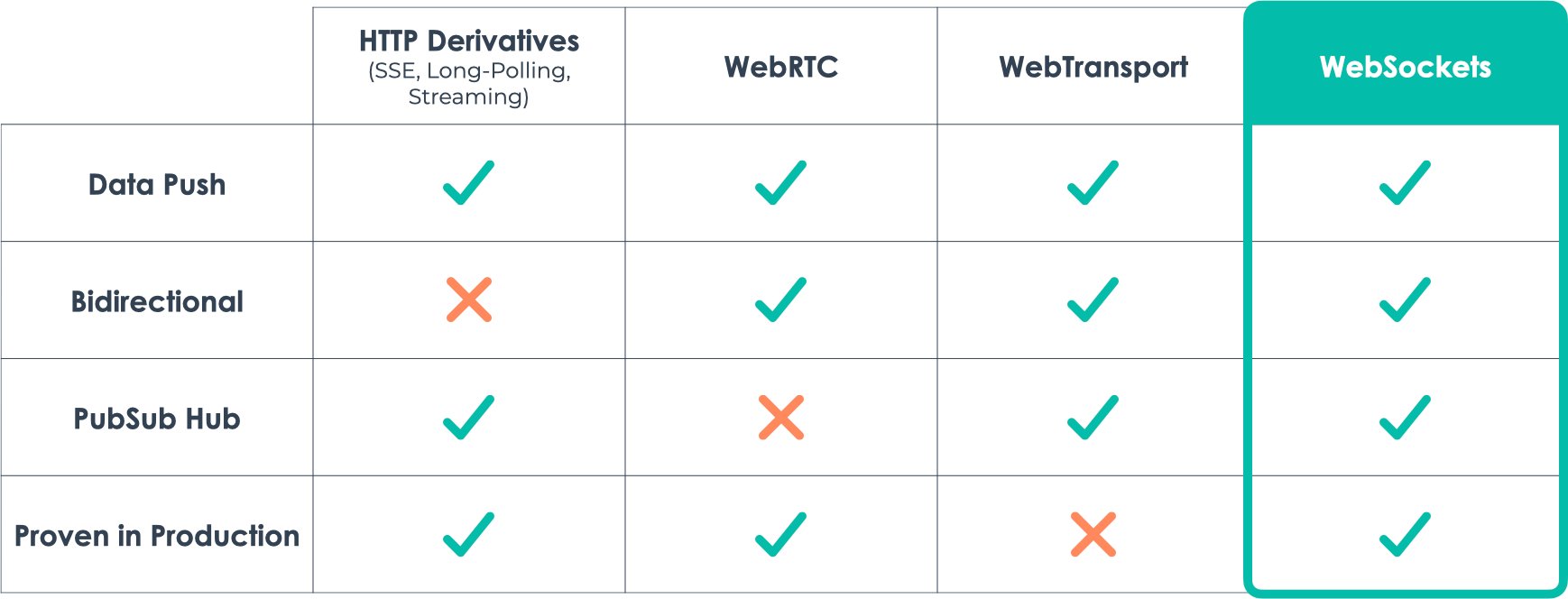
3.8 WebSockets
There are a number of communication protocols that can be used to
build a real time application including HTTP derivatives, WebRTC,
WebTransport, and WebSockets. But for our use case, realtime
applications that have a hub which manages the realtime messages of
many publishers and subscribers, WebSockets is the logical, and most
common choice.
The need for bi-directional communication rules out the HTTP
options; there are some (hacky) workarounds to get these to simulate
bi-directional communication, but it would not be considered a
typical implementation. WebRTC is a peer-to-peer protocol but isn’t
used for a central hub. WebTransport could work, but as of the time
of this writing, it is still an emerging technology that is not
typically used in production applications.
WebSockets, on the other hand, handle all of the above requirements.
This protocol is now supported in essentially
every modern browser
and there are solid open-source libraries that exist to handle
common use cases like
SocketIO.
The Pub/Sub hub outlined above has the complicated task of managing
WebSocket connections and messages for many publishers and
subscribers. In the next section, we will explain why this Pub/Sub
hub should be treated as a separate service that is often provided
by a third party.
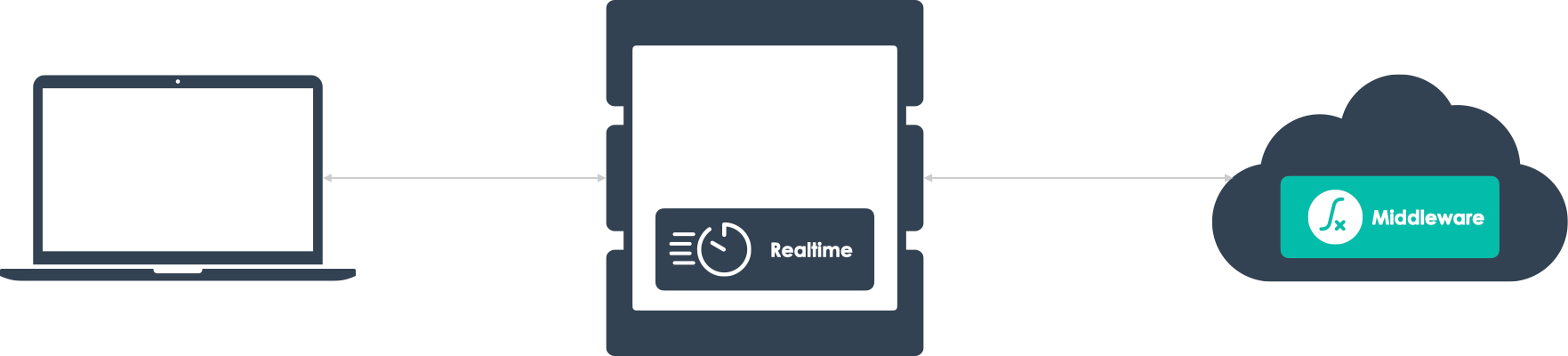
4. Dedicated Infrastructure for Realtime
At first glance, implementing realtime functionality for an
application is fairly simple. A library (like
SocketIO) can be
installed to manage Websocket connections and realtime messages.
This works well for a small application, with a small number of
publishers and subscribers. But eventually, coupling application
code with realtime management code (all on the same server) becomes
problematic.
As a realtime application becomes popular, the app server will need
to manage an increasing volume of realtime messages. Eventually, the
message load will become too great and (potentially) cause the app
server to crash.
The initial response might be to vertically scale, adding more
compute power to the app server. This works, up to a point, but it
eventually becomes evident that these two components -- the app code
and the realtime management code -- have different scaling needs.
Therefore, they should be treated as two separate services -- with
different compute needs -- that exist on two different servers.
Treating realtime as a separate service becomes increasingly
important when building multiple realtime applications. If realtime
management is not a separate service, both applications will contain
a redundant realtime management component. A separate realtime
service on the other hand, can manage the realtime messages for both
applications, without the need for redundant code.
When realtime applications become more popular, the realtime
management component may need to scale at a different rate than the
rest of the application. A separate realtime service can scale
independently from the applications themselves, eliminating the need
to scale up an entire monolithic application.
At first, a realtime service can be scaled vertically, adding more
compute power to the existing server. But, at a certain point,
vertical scaling reaches a limit and becomes financially infeasible.
Now, the only option is to horizontally scale the realtime service.
A horizontally-scaled realtime service introduces new problems as a
result of WebSocket connections now being distributed across
multiple server instances. (We will explain more about these
challenges later.)
It’s at this point that developers often not only need a separate
realtime service, but a realtime infrastructure-as-a-service
provider. This way, developers can focus on building their realtime
applications rather than managing realtime infrastructure.
To summarise, having dedicated infrastructure for realtime offers:
Flexibility (by decoupling the realtime needs
from that of the application, you can scale each part up and down
as needed)
Less Complexity (separating out the services
means that you have a better sense of what each part is doing;
developers can focus on their applications instead of
infrastructure)
Specialization Benefits (each part is able to do
what it does best, without interference from anything else, and
you can optimise for each particular service)
4.1 Existing Solutions
Companies like
PubNub,
Ably and
Pusher, three of
the major providers of realtime infrastructure-as-a-service, cater
to this need for a managed realtime infrastructure. They
advocate
decoupling realtime infrastructure from your application code “so
that product development teams can focus on innovation instead of
infrastructure.”
“so that product development teams can focus on innovation instead
of infrastructure.” - PubNub
These services host all required infrastructure needed for realtime
functionality, managing scaling and all the other concerns that take
developers away from focusing on their realtime apps. Developers
simply connect to their API endpoints and route all realtime data
through that service.
There are also self-deployable options for realtime infrastructure
which accordingly offer more control, albeit at the potential
expense of more configuration and deployment issues.
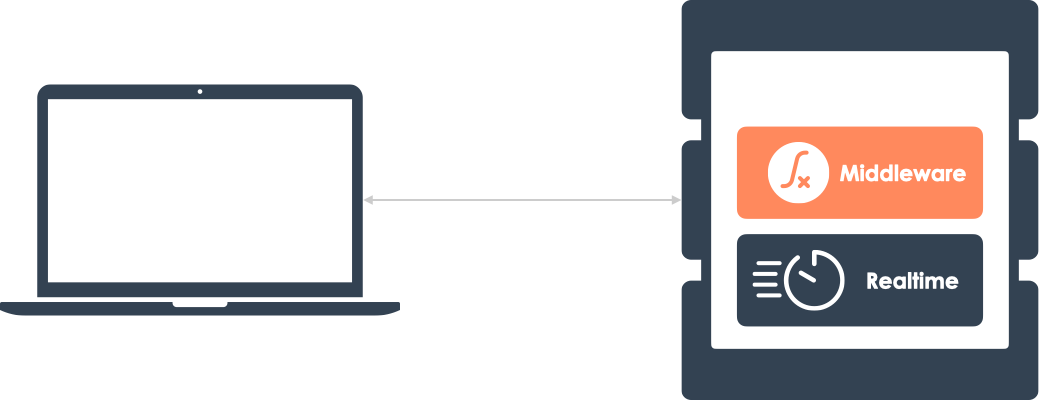
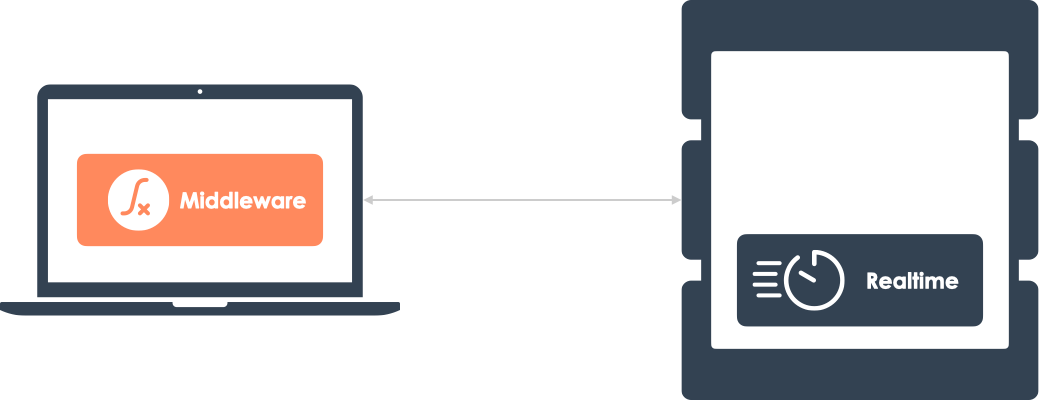
5. Realtime Middleware
There’s one last important component of realtime that has not been
mentioned. Realtime messages often require in-transit message
processing. When a message is published, it might need to undergo
some type of analysis or transformation before being received by
subscribed clients.
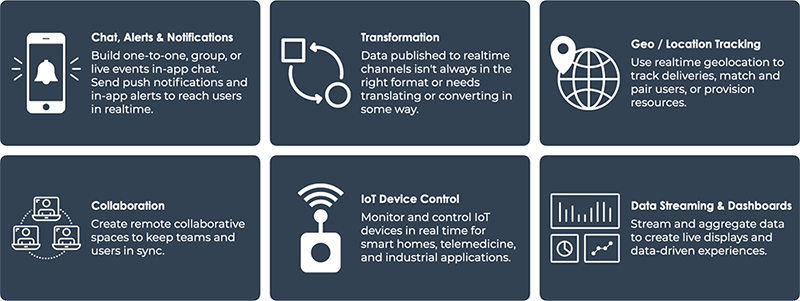
5.1 Realtime Middleware is Everywhere
The general pattern of performing some kind of computation on
realtime messages is widespread.
Here are some examples of common realtime middleware uses:
Filtering profanity out of chat messages
Enriching latitude/longitude coordinates with the demographic
information of that area
Translating a message in a chat app to a different language
Performing sentiment analysis on text with machine learning
Routing payment information to third parties such as Stripe
Responding to messages with chat bots
Sending alerts, given a particular trigger / condition
Some real-world examples of this middleware being used for specific
services include:
A large beverage company
that made a chat app for a big sporting event. They wanted to
filter any mention of their competitor out of the chat. So they
sent every message down to their servers which they had to spin up
and scale, strip out the name of their competitor, replace it with
their name, and republish the message back out.
Guild, a professional messaging/chat app, uses realtime middleware to
handle event-based triggers for their users
Onedio, an HQ-trivia app for 1 million players, uses realtime
middleware to route messages to AWS’ SQS with extremely low
latency, something they likely wouldn’t have been able to support
without it.
This need for realtime middleware was recognized by both of the
major realtime infrastructure-as-a-service providers, PubNub and
Ably. Both companies observed that their customers often needed to
perform a small bit of processing on their realtime messages.
“A common requirement in realtime messaging applications is to be
able to insert some business logic into a message processing
pipeline.” -Ably
5.2 The Realtime Middleware Antipattern
PubNub and Ably recognized the need for realtime middleware when
they noticed
an interesting anti-pattern
emerge with how their customers were using their services.
Recall that PubNub and Ably’s services allow customers to decouple
their application infrastructure from their realtime infrastructure
as described above. However, they observed the users of their
services were sending every single message down to their own app
servers to perform some kind of processing or compute on those
messages. This reintroduced a lot of the same problems that existed
when things were tightly coupled. Now their customers found they had
to pay closer attention to the scaling needs of their service as it
became overburdened with this increased load.
"You see everyone publishing down to their servers doing a small
little bit of processing and then publishing the message right back
out... It doesn't make sense to be funneling all of your data back
down to a small number of servers, scale those out as needed,
process and then republish back out... so, this [PubNub Functions]
is absolutely required." (PubNub CEO, Todd Greene)
5.3 Existing Solutions
PubNub and Ably set out to solve this problem by offering realtime
middleware as part of their real time infrastructure-as-a-service.
To understand the solution that both companies landed on, it helps
to understand the requirements that this realtime middleware has.
It needs to be easy for developers to use and update
It needs to exist in a secure environment
Each piece of middleware needs to be modular, reusable, and
independently scalable
The reasons for these requirements can be easily understood with an
example.
Imagine that a developer is building multiple realtime apps that are
completely unrelated, for example a chat app that filters out
profanity from all its messages and a geolocation app that
transforms GPS coordinates to directions. Later, they find that they
have European users and want to translate messages from both apps to
several European languages. This developer also plans on building
more realtime apps in the future, with either completely new
features and/or possibly reusing previously-created middleware.
It is helpful to think of these realtime middlewares as separate
services. In the above example, there is a profanity filter service,
a directions service, and various language translation services.
Each middleware only needs to perform some small amount of
processing, but needs to be able to scale up and down,
independently, on demand.
There are four places that a realtime infrastructure-as-a-service
provider could put realtime middleware:
In the client-side code
In the server-side code
On a dedicated server for realtime middleware
In Serverless Functions
The first option, putting realtime middleware in client-side code, is
a non-starter. Putting business logic in client-side code is not a
good practice because it introduces performance problems and security
concerns. In the
words
of PubNub founder Stephen Blum
“You want that code to execute in a trusted environment, not on a
client mobile device, which is uninterested code execution, because
those things are hackable and crackable. You want it to store your
business logic in a place that it just can't be tampered with.”
The second option of putting realtime middleware on the realtime
server doesn’t work either. This is because it is not feasible to
perform these message transformations directly on realtime servers.
There are several reasons for this:
Customization: Different customers have different
business needs for how their messages should be transformed and
interacted with. It is not practically possible for clients to
create custom code within these service providers’ server
codebase, and it is not possible for the service provider to
predict all customer needs and create the functions for them.
Security: Running customer code directly on the
realtime servers would present a significant risk. The service
provider would have to guard against both accidental disruptions
to the core code base as well as malicious attacks through this
access point into the realtime servers.
Separation of concerns: Running business logic
code on the realtime servers would tightly couple the message
delivery architecture to the business logic code. Both the
business logic execution and the message delivery performance
would be susceptible to decreased performance if it were sharing
resources with the other task. Additionally, these two tasks would
not necessarily scale in the same way or at the same time.
The third option, to put realtime middleware on a dedicated message
processing server wouldn’t be an ideal solution either. Although
this solution would decouple realtime management from realtime
message processing, all of the realtime middleware would be tightly
coupled on one server. Because each middleware should be treated as
its own modular service with different scaling needs, it doesn’t
make sense to put them all on the same server.
The last option, serverless functions, is a perfect fit for realtime
middleware because it is secure, modular, and easy for developers to
customize.
Serverless functions are elastic compute hosted by a third party
that have several properties that make them ideal to use as realtime
middleware.
They usually have small or compact use cases and as such are not
designed for persistence, but rather atomic ‘throwaway’
operations, albeit ones that can be readily reused.
They spin up on demand and are independently scalable.
They are easy to package and deploy.
The cost of running them is allocated per unit of time and as a
result they are potentially lower cost, since you only pay for
what you use.
These properties make them ideal for the purposes of realtime
middleware. With serverless functions, developers can easily create
and update realtime middleware without posing a security risk to the
realtime infrastructure. Each serverless function can be treated as
its own separate service that spins up and scales, independently, on
demand. Resultantly, they can be used by not just one, but multiple
applications for similar messages processing needs. And because
serverless functions scale up on demand and charge based on compute
time (or invocation frequency in the case of Cloudflare), developers
don’t have to worry about paying for idle compute resources.
It’s worth noting the limitations of serverless functions; they
aren’t a silver bullet. They aren’t ideal for processes requiring
large amounts of compute; there are maximums for length of compute
and size of payload. They also add some complexity to the
infrastructure and as a result can be harder to test and debug. They
live on servers with other people's code so there can be security
concerns. Since they are ephemeral, any initial execution can have a
slight lag -- the so-called ‘cold start’. Given these limitations,
though, the benefits of serverless functions outweigh the
disadvantages for this use case.
Although both companies used serverless functions to provide
realtime middleware for their customers, they did so in very
different ways.
PubNub created
PubNub Functions
which are proprietary serverless functions, created and deployed
within PubNub. They
characterized
it as “the idea of using an eventive model of programming so that
you are rewriting data as it goes through the network and then
publishing it out." Elsewhere, PubNub’s CEO
stated:
“If there wasn't a concept called serverless, we would still want to
go down this path that we went down. Being able to give your
customer the control of how the network is involved and shaped is
very important, especially since you need somewhere to host your
trusted code. You want that code to execute in a trusted
environment...”
Ably took a different approach: you create your own serverless
functions on one of the major serverless function providers’
infrastructure, and Ably lets you integrate these functions into
your Ably pipeline using
Reactor Integrations.
We took the solutions proposed by Ably and PubNub as an opportunity
to explore the ‘realtime + middleware’ space. There were a number of
technical and practical problems that these third-party options had
solved, but we found a certain set of use cases where we had
something to offer.
6. Why We Built Ekko
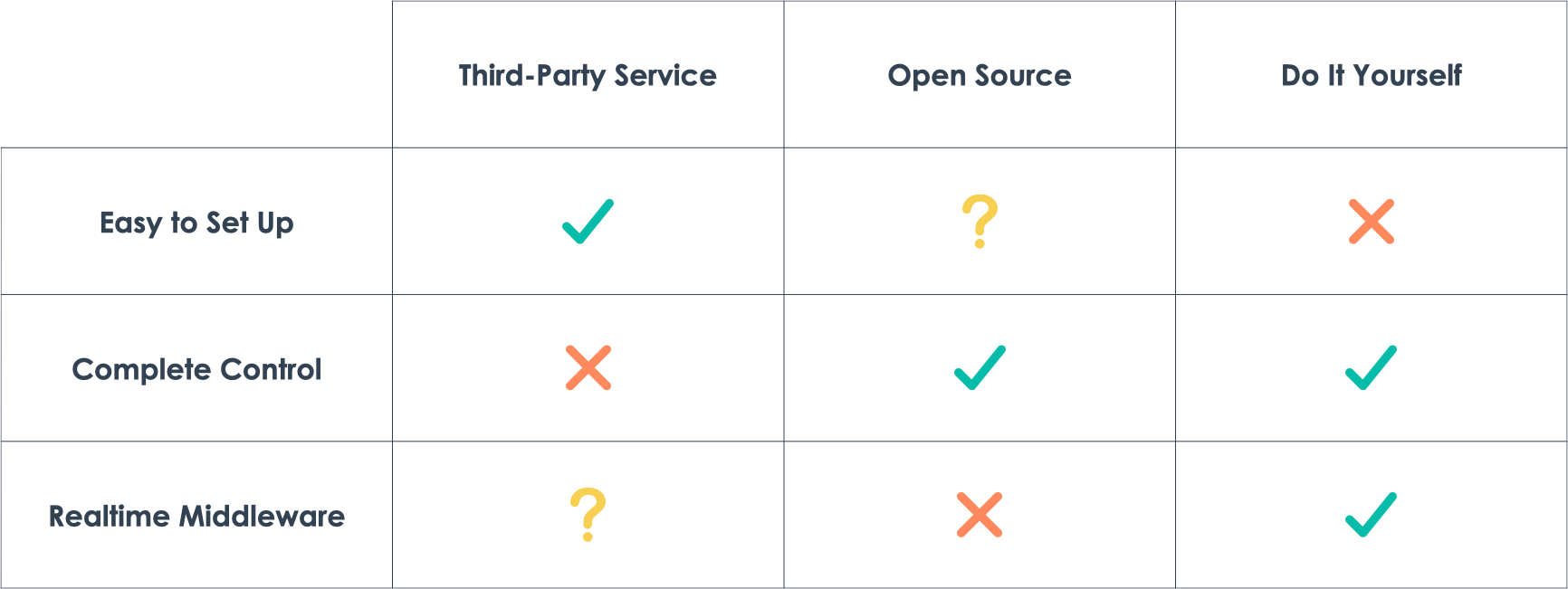
Developers building realtime applications can choose between three
main options: a third-party service, an open-source solution, or
do-it-yourself. The right choice depends on the specific use case.
If easy setup is most important, it’s probably best to go with a
third-party solution. There are good open-source solutions, but the
extent to which they are easy-to-use depends on each use case.
If complete control over data and infrastructure is important,
third-party solutions won't work. In this case, the only options are
open-source solutions or custom, self-built solutions.
If applications need realtime middleware, the choices become very
limited. Not all major third-party providers offer realtime
middleware out of the box, and there are currently no open-source
solutions that offer realtime middleware.
A custom built, in house realtime infrastructure is always an
option, and provides full control over infrastructure and data, but
this is a fairly ambitious undertaking.
We saw an opportunity to fill this gap in the market by building an
easy-to-use, open-source framework for self-deployed, realtime
infrastructure, with middleware. The result was Ekko: a realtime
framework for the in-transit processing of messages.
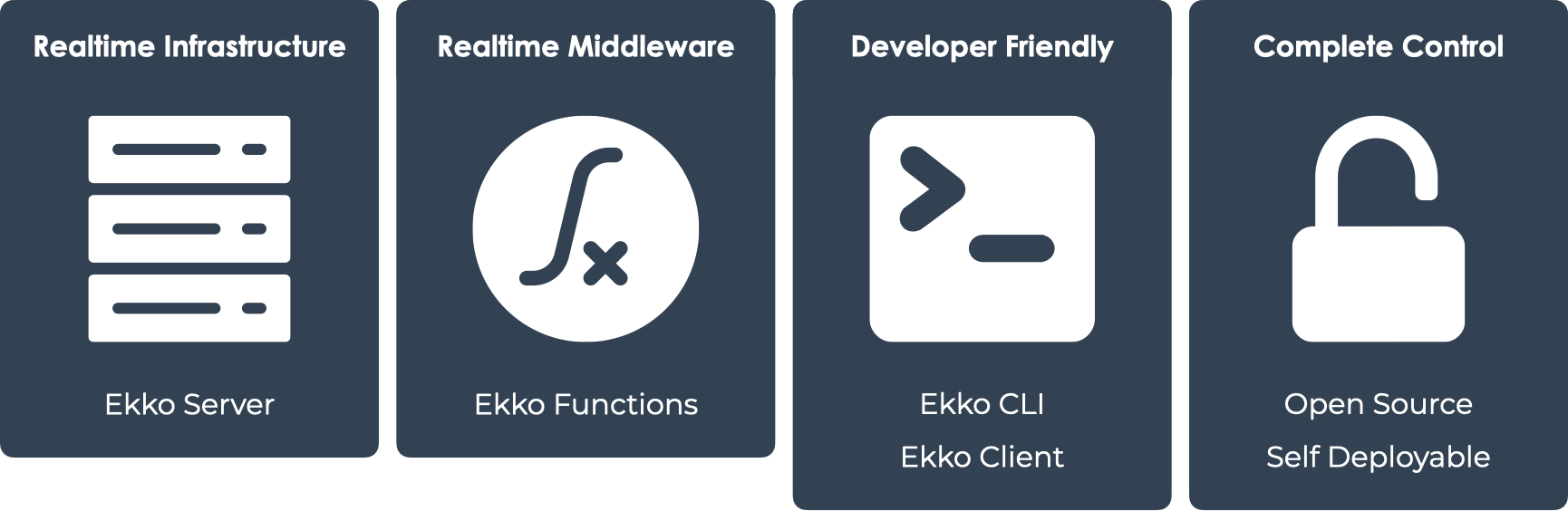
7. Using Ekko
There are four main parts to Ekko:
Ekko Server
Ekko Functions
Ekko CLI
Ekko Client
The Ekko Server manages realtime messages for applications with many
publishers and subscribers. It facilitates the processing of
realtime messages by invoking Ekko Functions.
Ekko Functions provide realtime middleware for in-transit message
processing. These functions are easy to create, update, and deploy
with the Ekko CLI tool. For complex workflows, developers can chain
multiple Ekko Functions together.
The Ekko CLI tool provides clear and simple commands that a
developer can use to manage Ekko Functions as well as spin up and
tear down the entire Ekko infrastructure.
Ekko Client enables developers to build realtime applications on top
of the Ekko Server. The Ekko Client exposes a handful of methods to
the developer, enabling clients to subscribe and unsubscribe to and
from channels, publish messages, and handle received messages.
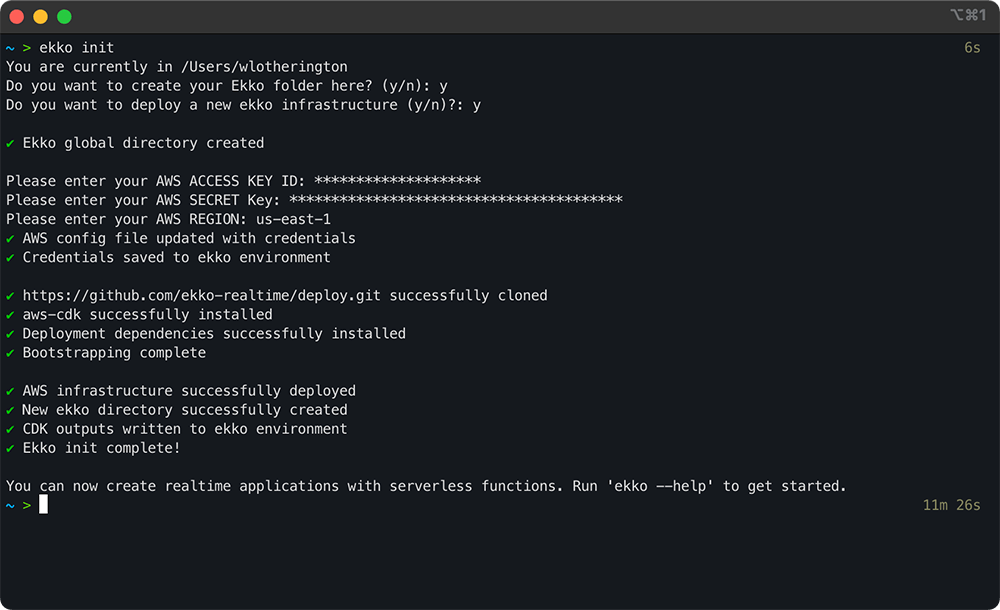
7.1 Deploying Ekko
The Ekko Server infrastructure can easily be deployed to AWS by
running the ekko init command using the
Ekko CLI tool.
The Ekko CLI prompts for AWS credentials and uses those, along with
AWS’ Cloud Development Kit (CDK), to deploy the Ekko infrastructure
to AWS.
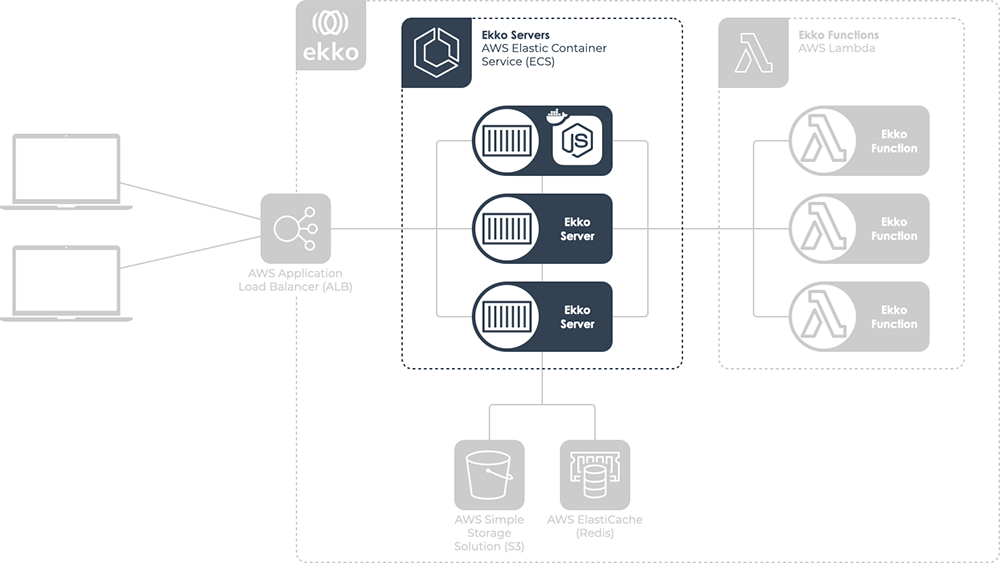
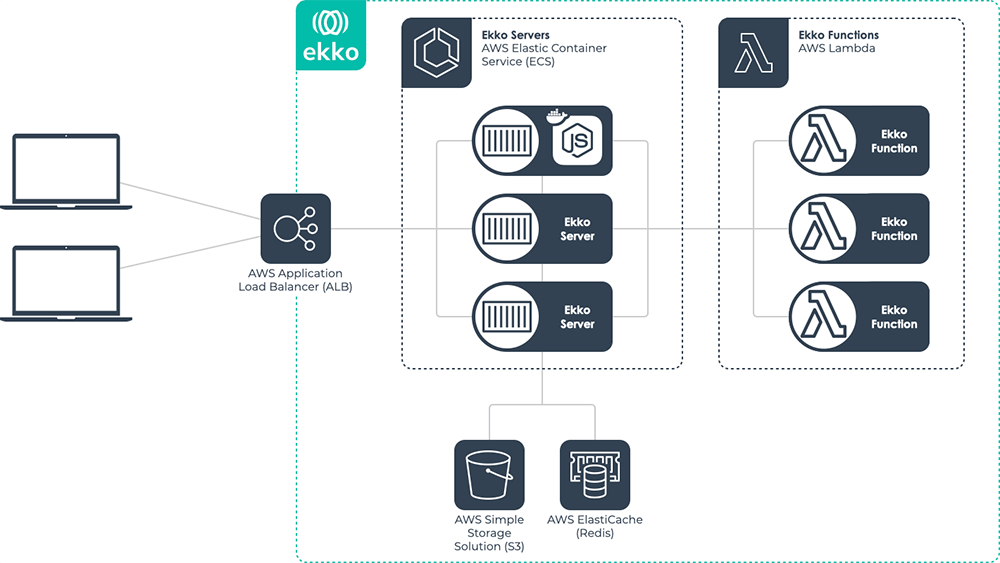
7.2 Ekko Infrastructure
This is the infrastructure deployed by ekko init.
The Ekko Server is a Node application deployed via container to AWS’
Elastic Container Service (ECS). The Application Load Balancer
distributes incoming WebSocket connections to the Ekko Server. We’ll
go into more detail on the importance of the S3 bucket and
ElastiCache instance in section 8.
7.3 Connecting an Application to Ekko Server
The Ekko Client is used to build realtime applications that make use
of the Ekko Server. Ekko Client can be
installed with npm
or imported via CDN.
Once Ekko Client is installed, it can be used to create a new Ekko
Client instance.
This Ekko Client Instance allows an application to connect, and send
realtime messages to the Ekko Server. Ekko Client takes a handful of
parameters including an app name, a host, a
JSON Web Token (JWT),
and an optional universally unique identifier (UUID). The app name
is the developers choice, and the host and JWT can be generated
using the Ekko CLI. The UUID is normally generated and passed in by
the developer. But, if a UUID is not passed to the Ekko Client
instance, Ekko Client will automatically generate one.
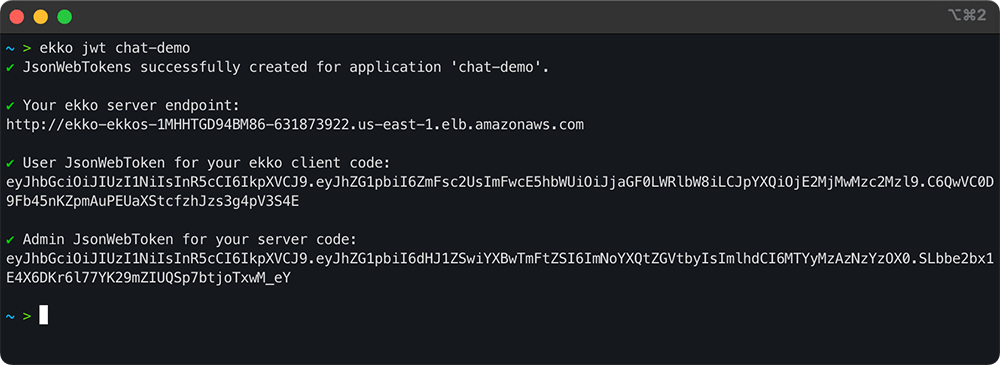
Retrieving the host and generating JWT values can be done by running
the ekko jwt command in the Ekko CLI.
The Ekko Server endpoint is retrieved by the CLI from a local
environment variable that is generated when the Ekko infrastructure
is deployed. This is the URL for the Application Load Balancer that
proxies WebSocket connections to the Ekko Server. Passing this value
as the host to the Ekko Client, enables it to connect and send
realtime messages to the Ekko Server.
The CLI tool generates JWTs using a secret that is generated when
the Ekko infrastructure is first deployed. Passing in an admin
token, instead of a user token, gives access to status events,
including connect, disconnect and error messages.
Once an Ekko Client instance has been created, it exposes several
methods that you can use to interact with the Ekko Server. With
these methods, the client can subscribe and unsubscribe from
channels, publish messages, and handle messages of different types.
This is what it looks like when we have two clients connected to the
Ekko Server, subscribed to the same channel, publishing messages on
it.
7.4 Deploying Ekko Functions
To process realtime messages in transit, Ekko Functions need to be
deployed to AWS Lambda. When the Ekko infrastructure is deployed
with the ekko init command, it creates an
ekko/ekko_functions directory locally. From this
directory, create, update,
deploy, and destroy commands can be run to
manage Ekko Functions.
Ekko Functions are created with a default file structure and format
so that they can be deployed to AWS Lambda. These functions can be
as simple as the example below, or a complex program with multiple
files. In this example, the demo-angry function exists in an
index.js file and simply takes the message payload,
capitalizes the text, and adds a few exclamation points.
Once Ekko Functions are created, they can easily be deployed to AWS
Lambda with the ekko deploy command. After Ekko
Functions have been deployed, the
associations.json file in the
ekko_functions directory needs to be manually updated.
associations.json informs the server what functions it
should use for processing messages published to a specific channel.
Once this file has been updated, the
ekko update associations.json command can be run which
stores the file on the S3 bucket mentioned earlier, and caches it on
the Ekko Server.
7.5 Transforming Messages in Realtime
After creating and deploying Ekko Functions, this is what the Ekko
infrastructure and message processing flow looks like:
Now, when a client sends a message on the Angry channel, the server
forwards that message on to the Angry Lambda for processing. The
Angry Lambda sends the processed message back to the Ekko Server
which then emits the message out to all subscribed clients on the
Angry channel. The same occurs on the other two channels. The server
knows which functions are associated with which channels using
associations.json.
If you want to teardown your Ekko infrastructure, you can do that
with the ekko teardown command. This will tear down
your Ekko Infrastructure and all Ekko Functions deployed to AWS
Lambda.
As you can see, deploying your own realtime infrastructure and
managing realtime middleware is easy to do with Ekko. You have now
seen what Ekko is and how it works. In the next section, we show
three areas where we faced challenges while building Ekko.
8. Engineering Challenges
We faced several engineering challenges when building Ekko: how to
authenticate clients connecting to our server, how to associate
individual Ekko Functions with specific realtime channels, and how
to scale the infrastructure.
8.1 Authenticating Clients
Once we created an Ekko Server to manage realtime communication and
an Ekko Client API that developers could use to build realtime
applications, we faced the problem of authentication. With the
current design, Ekko Clients send messages to the developer's Ekko
Server endpoint. But the problem with this is that anyone can send
messages to this public endpoint, including bad actors.
To validate Ekko Clients, we decided to use JSON Web Tokens (JWTs).
These are essentially API keys that can have a JSON object encoded
into it -- the data isn't private, but you can't change it without
breaking the API key. When the Ekko infrastructure is deployed, a
secret key is generated and stored as an environment variable on
Ekko Server and the CLI tool. When a developer runs the ekko jwt
command, the CLI tool uses the secret to generate app specific JWTs
that can be passed in to a new Ekko Client instance. The Ekko server
uses the same secret to authenticate JWTs and only allows clients
with a valid JWT to connect to it.
Since we can encode data into the JWT, we used it to specify if the
connecting client was an admin or a normal user, and what app they
were allowed to access. This gave us basic app- and role-level
security.
8.2 Ekko Function Management
Like PubNub and Ably, we decided to use serverless functions to run
our realtime middleware code. But, we still needed to figure out how
to coordinate message processing. How would Ekko Server know which
messages needed to be processed by which functions?
8.2.1 Linking Ekko Functions with Messages
Since clients publish and subscribe to channels, it made sense to
link specific channels with specific Ekko functions. So if you’re
making a chat app that uses a profanity filter, you can create a
channel and all messages published to that channel get processed
with the profanity filter middleware. All subscribers to that
channel will receive the processed message.
We created an associations.json file to store these
associations between channels and functions.
associations.json is organized by application. Each
application has an array of channels, and each of those channels
contain an array of Ekko Functions to be used for that channel. With
this file, the Ekko Server routes messages from a specific channel
to the Ekko Functions associated with that channel. Once processed,
messages are returned to the Ekko server and emitted to all
subscribed clients.
It’s worth noting that multiple functions can be chained together
and the Ekko Server will route messages to all of the functions, in
order, before emitting the processed message back out to
subscribers.
8.2.2 Storing associations.json
The associations.json file is stored in an S3 bucket
and the developer is responsible for updating it locally and then
uploading it with the Ekko CLI tool.
8.2.3 Updating associations.json
We opted to cache the associations data on the server since we want
to minimize the amount of time it takes to process messages. But we
needed to figure out how to update the server nodes when a change
was made to the JSON file.
We looked at two ways for pushing the data to the Ekko Server. The
first option was to use the AWS service CloudWatch to send a message
through Simple Notification Service (SNS), another AWS service,
every time the S3 bucket registered an upload event.
The second option was to update the Ekko Server directly at the same
time that we upload the new JSON file to the S3. This would involve
sending a PUT request to the Ekko Server with the JSON
object as the payload. We could just add this behind the scenes in
our CLI tool when the developer uses the
ekko update command. This was the option we chose since
it didn’t add any complexity to our infrastructure. The
associations.json file is sent as a JSON Web Token, and
the code for the PUT route on the server verifies it is
a valid token (in addition to decoding it and using that payload as
the new function-channel associations data.
8.3 Scaling Ekko
The final engineering challenge we needed to handle was around
scaling Ekko. We wanted the deployed infrastructure to be able to
scale up and down as needed. If there were more users connecting to
the realtime server, we needed to be able to support those
simultaneous connections, and if there was an increased volume of
messages passing through the server, we needed to be able to support
the speedy transmission of those messages as well as any
transformations or in-transit processing.
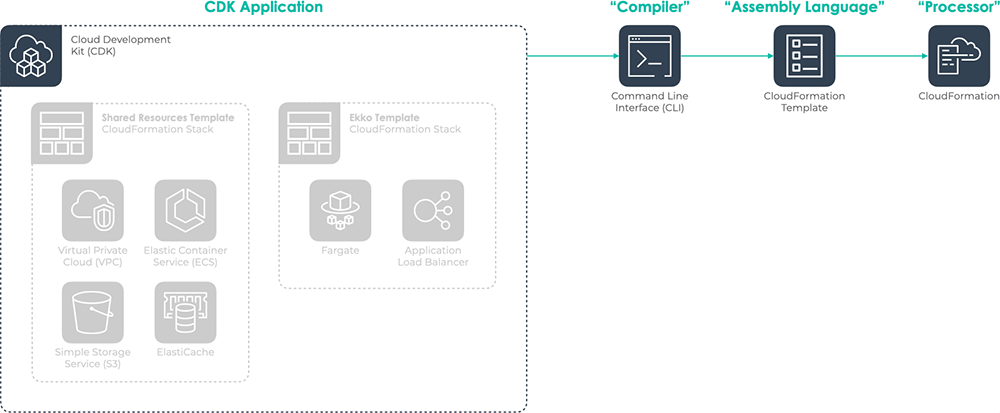
8.3.1 Deploying to AWS using CDK
Most of our scaling needs were handled by the choices we made when
deploying our infrastructure to AWS. We used AWS' Cloud Development
Toolkit (CDK) which synthesizes CloudFormation templates and then
deploys those constructs to AWS.
We didn't want to have to deploy our scalable infrastructure
manually, using the AWS web interface. Options available to us
included something platform agnostic like
Terraform or
the AWS homegrown equivalent,
CloudFormation
templates. CDK is a way to define those CloudFormation templates
using ordinary JavaScript code; it was appealing not to have to
handle the complexity of writing extremely long CloudFormation
templates from scratch and instead to define the infrastructure
'constructs' we wanted to provision.
8.3.2 Scaling the Ekko Server
The main part of Ekko that needed to be able to scale was the Ekko
server. We needed to support a flexible number of users connecting
to the realtime service as well as an increased volume of messages
being published.
In order to be able to scale flexibly, an attractive option for
horizontal scaling was to package up our server application as a
Docker container and then use AWS Fargate to scale those server
'tasks' up and down according to how taxed the particular task
instance became.
Fargate scales according to rules defined to account for how much
CPU and memory each container instance is using. We can specify
minimum and maximum boundary values to constrain how many containers
AWS can run. Fargate is not always completely transparent to use,
but it does handle our core problem of wanting to horizontally scale
our Ekko Server.
8.3.3 Establishing WebSocket Connections
Our next challenge came from the way our load balancer was routing
incoming connections and how that disrupted our need for persistent
WebSocket connections.
Socket.IO makes one request to set a connection ID, and a subsequent
upgrade request to establish the long lived WebSocket connection.
These two requests must go to the same backend process, but by
default our load balancer — AWS' Application Load Balancer — may
send the two requests to different Fargate container instances, so
the connection may not be successful.
When we first tried out Ekko on AWS infrastructure we could not
establish WebSocket connections for this reason.
The fix for this was to enable sticky sessions as a policy for our
Fargate task definition. We updated our CDK code to specify this
sticky property. Now each Ekko client gets routed to the same server
instance to which it was initially assigned and WebSocket
connections work as they should.
8.3.4 Scaling WebSocket Connections
Once our infrastructure was deployed, we wanted to make sure our
original server code continued to function as designed. Scaling to
multiple instances of the Ekko server presented an immediate
problem: how would all server instances know which messages were
being published on the various other instances?
This animation illustrates the problem of scaling WebSockets:
If we have two instances of the Ekko server, the load balancer is
going to connect one user to server instance A and the other to
server instance B. In this scenario, they are both subscribed to the
same channel so that they can chat with each other. Alice has a
WebSocket connection to server A and when she publishes her message,
server A receives it and publishes that message to the channel so
that all subscribers will receive it. However, only the WebSockets
connected with server A will get that message, so Bob won’t receive
it since he’s connected to server B.
In order to solve this problem, we used the Socket.IO Redis adapter
library. This library uses a Redis instance to broadcast events to
all of the Socket.IO server nodes.
Alice’s message, published to server node A, is automatically
published to server node B and emitted out to all subscribers.
8.3.5 Syncing Associations Data
A final engineering challenge we encountered was figuring out how to
synchronise state between all our Ekko Server instances.
Specifically, we needed to ensure that all server instances had the
latest version of the associations.json data (which pairs channels
with the Ekko Functions that will execute on all associated messages
passing through).
When updates are made to the associations.json file, we
use the CLI tool to upload these updates to the S3 bucket for
storage. We also let the Ekko Server know by sending a
PUT request with the new associations data as the
payload. In this way, the current server uses the data sent via the
PUT request, and new server instances spinning up will
use the latest version of the associations data in the S3 bucket.
However, we had a problem. The request will be routed to just one of
the Ekko Server instances. We need to be able to notify all of the
Ekko Server instances with the updated data. As you can see from the
animation, our PUT request does update one of our
server container instances, but this update isn't shared with the
others.
Our solution to this was to use the standard Redis package. The
server that receives the message publishes the file to the Redis /
ElastiCache cluster, and all the other server instances in turn are
subscribed to the Redis cluster and receive a copy of the new
associations data. This allowed us to keep our server instances
synchronised.
Solving these various engineering challenges allowed us to build
Ekko out such that it was working as we hoped, and it was also able
to scale. At this point, we wanted to make sure that the service as
a whole could function under realistic use loads.
9. Load Testing Ekko
We wanted Ekko to be able to manage thousands of WebSocket
connections to be viable as a realtime message processing framework.
In addition, we wanted it to handle and route hundreds of thousands
of messages in a short amount of time, all while invoking Lambda
functions for in-transit message processing. To test all of this, we
used the
Artillery.io load testing library.
We
set out
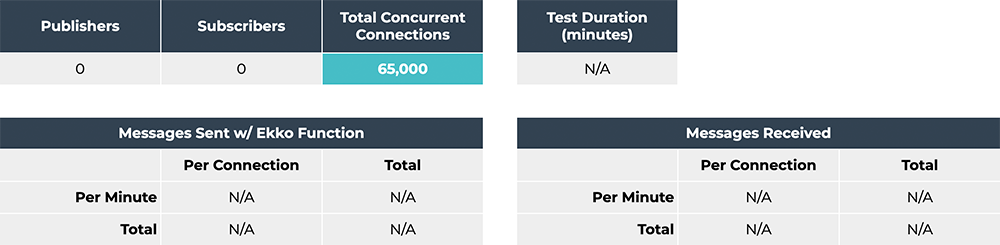
to see how many WebSocket connections Ekko could handle. We ran into
a hard limit of 65,000 connections per Ekko Server container.
Attempting to establish more than 65,000 connections resulted in
WebSocket errors. We subsequently learned that other developers had
come across this unwritten AWS limit in
their own projects. Although Ekko -- and the underlying infrastructure -- could
almost certainly be modified to remove this limit, we decided that
65,000 connections was enough for our use case.
Next, we wanted to test a common use case for a realtime message
processing service: many connected devices sending messages to a
realtime service for some kind of data processing or monitoring.
Note that in this scenario, there are many publishers generating
data for processing, but they are not subscribers. So, there is no
data being published back out to the connected devices from the
server.
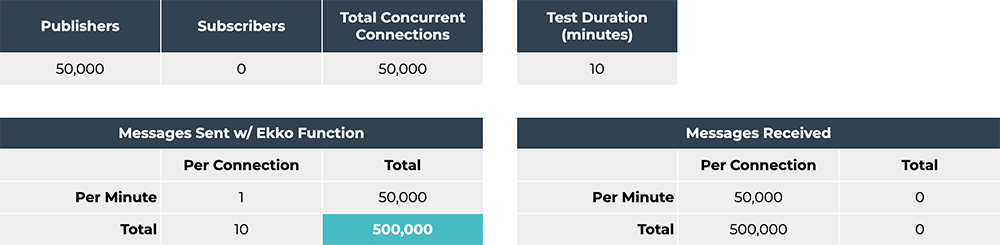
In this test, we established 50,000 concurrent WebSocket
connections. Each connection published one message per minute for
ten minutes. Each of these messages were processed by an Ekko
Function deployed on AWS Lambda. The result was 50,000 concurrent
WebSocket connections sending a total of 500,000 messages to the
Ekko Server which transformed them -- a total of 500,000 Lambda
invocations over the course of ten minutes. During the test, AWS’
ECS spun up two additional Ekko Server containers to deal with this
load.
Finally, we wanted to test Ekko’s ability to handle the many
publisher, many subscriber use case that you would find with chat
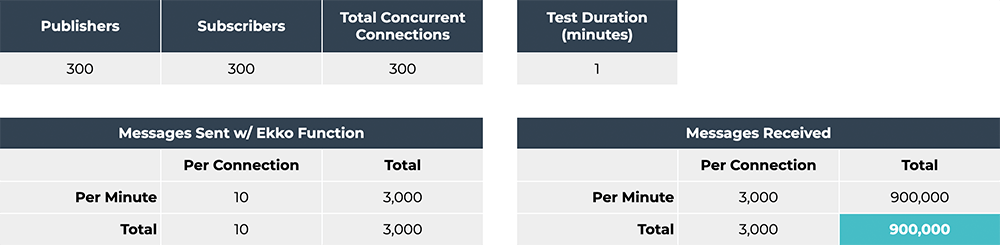
apps. We started by testing 300 connections that all subscribed to
the same channel. Each connection sent 10 messages over the course
of a minute, for a total of 3,000 published messages.
Ekko Server was able to handle this without issues, only reaching
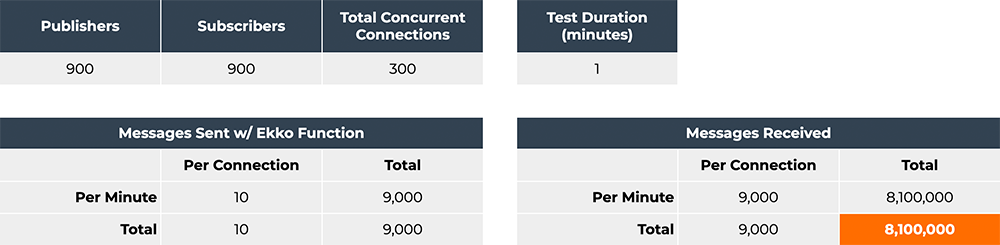
15% of its maximum CPU usage at peak. When we ran the same test with
900 connections, it maxed out the CPU before ECS and Fargate could
scale up. We realized that we were seeing a quadratic increase in
load with each additional subscriber. In the first test, Ekko Server
had to send 3000 messages to 300 subscribed clients, totaling
900,000 messages sent from the server. In the second test, it had to
send 9000 messages to 900 clients, totaling 8,100,000 messages.
Seeing how quickly load was increasing with additional connected
clients, we thought more about our use case. If you consider a chat
app like Slack, you realize that it is not common for users to be
continually sending messages. Instead, over the course of a day, a
user might send a few dozen messages. On average, a user might
receive a message a minute.
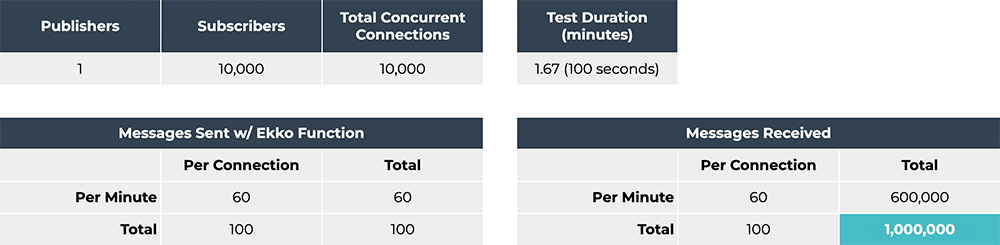
With this updated use case, we ran another test. We connected 10,000
clients that all subscribed to the same channel. We then connected
one client that published one message per second to all 10,000
clients. This resulted in Ekko Server sending 10,000 messages per
second for 100 seconds, totalling in 1,000,000 messages. This was
more than enough to justify the chat app use case and Ekko Server
only reached 50% CPU usage so we remained within reasonable ranges.
During our tests, ECS did scale up Ekko Server instances according
to the scaling policies defined by our CDK code. However, it became
apparent that different applications have different scaling needs. A
developer using Ekko will therefore most likely want to customize
their ECS scaling policies to suit their needs. For example, if you
anticipate consistently having over 100,000 connected clients, you
may want ECS to run a minimum of two or three Ekko Server containers
by default.
10. Future Work
Ekko is designed to solve the current use case we envisioned,
however we did notice some areas that we'd like to improve for
future iterations.
10.1 Message Persistence
Messages sent through Ekko are currently not stored anywhere. Ekko
simply acts as a hub and passes them on to whichever clients are
subscribed to the service. This was a design choice for our current
version: we chose to prioritise the message transmission speed and
the transformation functionality over any attempts to provide
durability or redundancy of the data passing through the Ekko
Server.
Simply storing every message somewhere on AWS infrastructure — S3
buckets or even DynamoDB — would be relatively easy to implement,
but using those within the context of the realtime service is a more
difficult problem. Which is to say, message persistence for the
purpose of simply logging message content is a much less problematic
planned feature than message persistence for the purpose of handling
dropped connections and the redelivery of messages missed while a
client was offline (for example). The exact scope of implementing
message persistence therefore depends quite a bit on what message
persistence is being used for.
10.2 Message Encryption
The Ekko Server currently has access to all messages sent through it
(providing they weren't already encrypted on the client side).
Encryption of user data is largely recognised as something that
should happen by default and not be offered as an afterthought.
For our use case, encryption of realtime data was not the core
problem we set out to solve, but in order to fill out the features
of Ekko we think that it is among the more important parts to
address. We would like to add TLS connection security by default,
the encryption of messages passing through the Ekko system as well
as more fine-grained access controls for users and developers.
10.3 In-order Delivery of Messages
Ekko currently prioritises the speedy — realtime — delivery of
messages rather than making sure those messages are delivered in
order. This is a tradeoff that most of the major realtime companies
concede, suggesting that users of their services add an incrementing
serial number to each incoming message so as to be able to ascertain
the order in which they were received.
For Ekko, messages can and will often be transformed in some way.
This means sending them off to an AWS Lambda function to be
transformed or acted upon, which can take a variable amount of time.
This is above all what might be responsible for causing messages to
be delivered out of order.
Developers using Ekko could implement their own variant of
incrementing message serial ids (as recommended by Pubnub and Ably),
but we would like to provide an option for in-order message
delivery, backed by whatever extra infrastructure is necessary.
11. Conclusion
Ekko is an open-source framework allowing developers to easily add
realtime infrastructure and in-transit message processing to web
applications.
We hope you have seen how flexible Ekko is to work with. The
possibilities available to you are many, as you can see from some of
the following examples.
The combination of a realtime server with serverless functions as a
kind of middleware for in-transit processing of messages offers a
rich palette of options from the very start. We look forward to
hearing what you build with Ekko!
Presentation
Meet our team
We are currently looking for opportunities. If you liked what you
saw and want to talk more, please reach out!



 The first option, putting realtime middleware in client-side code, is
a non-starter. Putting business logic in client-side code is not a
good practice because it introduces performance problems and security
concerns. In the
The first option, putting realtime middleware in client-side code, is
a non-starter. Putting business logic in client-side code is not a
good practice because it introduces performance problems and security
concerns. In the